UFLDL深度学习笔记 (四)用于分类的深度网络
1. 主要思路
本文要讨论的“”基本原理基于前2节的和 ,区别在于使用更“深”的神经网络,也即网络中包含更多的隐藏层,我们知道前一篇“无监督特征学习”只有一层隐藏层。原文不仅给出了深度网络优势的一种解释,还总结了几点训练深度网络的困难之处,并解释了逐层贪婪训练方法的过程。关于深度网络优势的表述非常好,贴在这里。
使用深度网络最主要的优势在于,它能以更加紧凑简洁的方式来表达比浅层网络大得多的函数集合。正式点说,我们可以找到一些函数,这些函数可以用\(k\)层网络简洁地表达出来(这里的简洁是指隐层单元的数目只需与输入单元数目呈多项式关系)。但是对于一个只有\(k-1\)层的网络而言,除非它使用与输入单元数目呈指数关系的隐层单元数目,否则不能简洁表达这些函数。
逐层训练法的思路表述如下:
逐层贪婪算法的主要思路是每次只训练网络中的一层,即我们首先训练一个只含一个隐藏层的网络,仅当这层网络训练结束之后才开始训练一个有两个隐藏层的网络,以此类推。在每一步中,我们把已经训练好的前\(k-1\) 层固定,然后增加第\(k\)层(也就是将我们已经训练好的前\(k-1\) 的输出作为输入)。每一层的训练可以是有监督的(例如,将每一步的分类误差作为目标函数),但更通常使用无监督方法(例如自动编码器,我们会在后边的章节中给出细节)。这些各层单独训练所得到的权重被用来初始化最终(或者说全部)的深度网络的权重,然后对整个网络进行“微调”(即把所有层放在一起来优化有标签训练集上的训练误差).
深度网络相比于前一篇“无监督特征学习”增加了隐藏层数,带来局部极值 梯度弥散问题,解决的办法就是将网络作为一个整体用有监督学习对权重参数进行微调:fine-tune 。值得注意的是,开始微调时,两隐藏层与softmax分类输出层的权重$W^{(1)}, b^{(1)}; W^{(2)}, b^{(2)}; \theta $不是用随机参数赋值的,而是用稀疏自编码学习获得的,和 的做法相同。
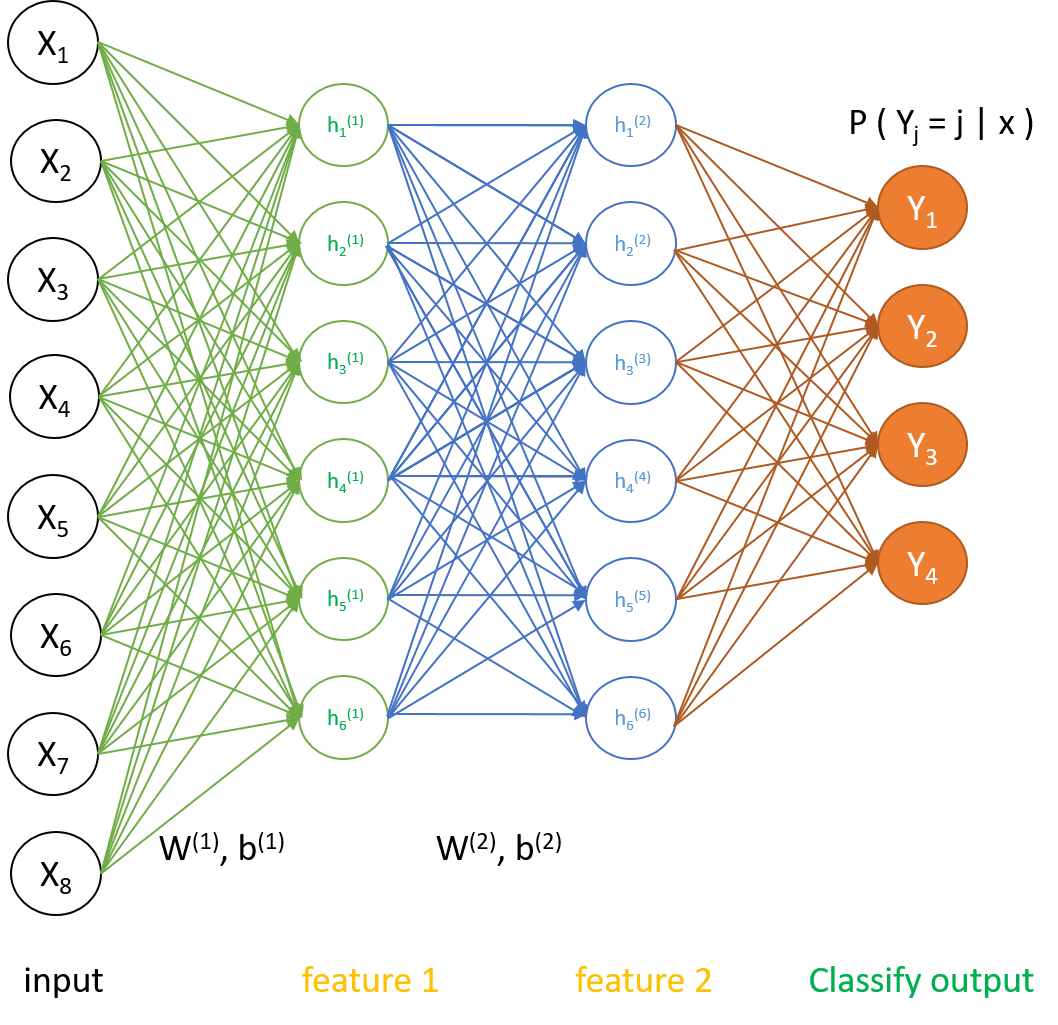
2. 训练步骤与公式推导
-
- 把有标签数据分为两部分\(X_{train},X_{test}\),先对一份原始数据\(X_{train}\)做训练,获得输入层到第一隐藏层的最优化权值参数\(W^{(1)}, b^{(1)}\)
-
- 将\(X_{train}\)前向传播通过第一隐藏层得到\(feature1\), 以此为输入训练第二隐藏层,得到最优化权值参数\(W^{(2)}, b^{(2)}\);
-
- 将\(feature1\)前向传播通过第二隐藏层得到\(feature2\), 以此为输入训练softmax输出层,得到最优化权值参数\(\theta\);
-
- 用\(W^{(1)}, b^{(1)}; W^{(2)}, b^{(2)}; \theta\)作为初始化参数,以\(X_{train}\)为输入,用后向传播原理给出整个网络的代价函数与梯度,在已知分类标签情况下微调权重参数,得到最优化参数\(W_{optim}^{(1)}, b_{optim}^{(1)}; W_{optim}^{(2)}, b_{optim}^{(2)}; \theta_{optim}\)。
-
- 用上述参数对测试集\(X_{test}\)进行分类,计算出分类准确率。
可以看出需要使用新公式的地方在于第4步,深度网络的代价函数的梯度,这里仍然运用最基础的梯度后向传播原理,从推导中我们知道输出层权重\(\theta\)梯度为
\[\begin{align} \frac {\nabla J} {\nabla \theta_j} &= -\frac 1 m\sum_{i=1}^m x^{(i)}\left [ 1\{y^{(i)}=j\} - p(y^{(i)}=j|x^{(i)};\theta) \right] +\lambda\theta_j \end{align}\]
矩阵化表达为:
\[ \begin{align} \frac {\nabla J} {\nabla \theta} &=-\frac 1 m (G_{k \times m}-P_{k\times m}) *X_{(n+1) \times m}^T +\lambda\theta \end{align} \]
使用 中相同的方法,推导残差后向传导形式,即可得到代价函数对\(W^{(1)}, b^{(1)}; W^{(2)}, b^{(2)}\)的梯度,
由于softma输出并没有用\(sigmoid\)函数,则激活值对输出值的偏导为1,输出层\(n_l=4\)
\[\begin{align} \delta_i^{(n_l)} &= -(y_i-a_i^{(n_l)})*f'(z_i^{(n_l)}) \\ &= -y_i-a_i^{(n_l)} \\ vectorize \\ \delta^{(n_l)} &= -(G_{k \times m}-P_{k\times m}) \end{align}\]
运用后向传导原理,第三层(第二隐藏层)的残差为
\[ \begin{align} \delta^{(3)} &= \theta^T*\delta^{(n_l)} .* f'(z_i^{(3)}) \\ &= \theta^T*\delta^{(n_l)} .*(a^{(3)}.*(1-a^{(3)})) \end{align} \]
根据梯度与残差矩阵的关系可得:
\[\begin{align} \frac {\nabla J} {\nabla W^{(2)}} & =\frac 1 m \delta^{(3)}*a^{(2)} \\ \frac {\nabla J} {\nabla b^{(2)}} &=\frac 1 m\delta^{(3)} \end{align} \]
同理可求出
\[\begin{align} \frac {\nabla J} {\nabla W^{(1)}} & = \frac 1 m\delta^{(2)}*a^{(1)} \\ \frac {\nabla J} {\nabla b^{(1)}} &=\frac 1 m\delta^{(2)} \end{align} \]
这样我们就得到了代价函数对\(W^{(1)}, b^{(1)}; W^{(2)}, b^{(2)}; \theta\)的梯度矩阵。可以看到softmax是个特例外,多层隐藏层形式统一,这样便于代码循环实现,这里对两层隐藏层的推导只是为了便于理解。
3. 代码实现
根据前面的步骤描述,复用原来的系数自编码模块外,我们要增加fine tune的全局代价函数对权重的梯度,实现代码为stackedAECost.m,详见
function [ cost, grad ] = stackedAECost(theta, inputSize, hiddenSize, ... numClasses, netconfig, ... lambda, data, labels,~) % stackedAECost: Takes a trained softmaxTheta and a training data set with labels,% and returns cost and gradient using a stacked autoencoder model. Used for% finetuning. % theta: trained weights from the autoencoder% visibleSize: the number of input units% hiddenSize: the number of hidden units *at the 2nd layer*% numClasses: the number of categories% netconfig: the network configuration of the stack% lambda: the weight regularization penalty% data: Our matrix containing the training data as columns. So, data(:,i) is the i-th training example. % labels: A vector containing labels, where labels(i) is the label for the% i-th training example% We first extract the part which compute the softmax gradientsoftmaxTheta = reshape(theta(1:hiddenSize*numClasses), numClasses, hiddenSize);% Extract out the "stack"stack = params2stack(theta(hiddenSize*numClasses+1:end), netconfig);% You will need to compute the following gradientssoftmaxThetaGrad = zeros(size(softmaxTheta));stackgrad = cell(size(stack));numStack = numel(stack);for d = 1:numStack stackgrad{d}.w = zeros(size(stack{d}.w)); stackgrad{d}.b = zeros(size(stack{d}.b));endcost = 0; % You need to compute this% You might find these variables usefulM = size(data, 2);groundTruth = full(sparse(labels, 1:M, 1));% forward propagationactiveStack = cell(numStack+1, 1);% first element is input dataactiveStack{1} = data;for d = 2:numStack+1 activeStack{d} = sigmoid((stack{d-1}.w)*activeStack{d-1} + repmat(stack{d-1}.b, 1, M));endz = softmaxTheta*activeStack{numStack+1};% softmaxTheta:numClasse×hiddenSize. Z:numClasses×numCasesz = z - max(max(z)); % avoid overflow while keep p unchanged.za = exp(z); % matrix product: numClasses×numCasesp = za./repmat(sum(za,1),numClasses,1); % normalize the probbility aganist numClasses. numClasses×numCasescost = -mean(sum(groundTruth.*log(p), 1)) + sum(sum(softmaxTheta.*softmaxTheta)).*(lambda/2);% back propagationsoftmaxThetaGrad = -(groundTruth - p)*(activeStack{numStack+1}')./M + softmaxTheta.*lambda; % numClasses×inputSizelastLayerDelta = -(groundTruth - p);%各层残差delta定义是J对各层z的偏导数,不是激活值a, 输出层残差delta是▽J/▽z,没有1/a(i,j) 这个系数lastLayerDelta = (softmaxTheta')*lastLayerDelta.*(activeStack{numStack+1}.*(1-activeStack{numStack+1})); % res of softmax input layerfor d = numel(stack):-1:1 stackgrad{d}.w = (activeStack{d}*lastLayerDelta')'./M; stackgrad{d}.b = mean(lastLayerDelta, 2); lastLayerDelta = ((stack{d}.w)')*lastLayerDelta.*(activeStack{d}.*(1-activeStack{d}));end%% Roll gradient vectorgrad = [softmaxThetaGrad(:) ; stack2params(stackgrad)];endfunction sigm = sigmoid(x) sigm = 1 ./ (1 + exp(-x));end 4.图示与结果
数据集仍然来自。

设定与相同的参数,输入层包含784个节点,第一、第二隐藏层都是196个节点,输出层10个节点。运行代码主文件 可以看到预测准确率达到97.77%。满足练习的标准结果。
我们来比较一下微调前后隐藏层学习到的特征有什么变化。
| 逐层贪心训练 | 微调后 | |
|---|---|---|
| 第一隐层 |  |  |
| 第二隐层 |  |  |
| softmax输出层 |  |  |
类似稀疏自编码对边缘的学习,上图的第一隐藏层特征可理解为笔记钩旋弧线特征,第二隐藏层就难以理解为直观的含义了,深层网络不一定每一层都能对应到人脑对事物的一层理解上,此外微调后似乎是增加了干扰,也期待大牛们能解释一下这些变化!